Emotions in the Machine – Part II: Making of the voiceover for The Green Spurt's game ending
In this follow-up, I document my process of generating a voiceover for The Green Spurt using Dia by Nari Labs, experimenting with audio prompts, non-verbal tags, and audio editing to craft a fitting emotional tone for one of the game’s ending scenes.


In Emotions in the Machine –Part I, I shared my first impressions of Dia, the open-source Text-To-Speech (TTS) model by Nari Labs that brings a new level of emotional depth to AI voices.
After seeing its potential, I decided to explore it further. In this follow-up, I document my process of generating a voiceover for one of the ending scenes in The Green Spurt Apple Vision Pro game. From experimenting with audio prompts and non-verbal tags, to stitching together the best segments in Audacity, this article offers a behind-the-scenes look at how I brought the final voiceover to life.
The exploration and my learnings along the way
Most of my exploration happened over a couple of late weekend nights. I started by checking out the official documentation available on GitHub, and for a deeper dive, I also joined their Discord server. This helped me get a much better understanding of how to use Dia effectively and its best practices.
At the moment of writing this, Dia can be used either by running the model locally from Github or by trying it out in the Hugging Face space.
Here’s a quick walkthrough of the interface, along with a few tips I learned along the way.
Input text
![Screenshot of Dia's "Input text" field, with a prefilled text "[S1] Dia is an open weights text to dialogue model. [S2] You get full control over scripts and voices. [S1] Wow. Amazing. (laughs) [S2] Try it now on Git hub or Hugging Face"](https://roxana-nagy.com/content/images/2025/05/Screenshot-2025-05-12-at-2.11.39-PM.png)
- This is where you put the text you want to synthesize. The model supports both single and multiple speakers using tags like
[S1],[S2], etc. It also allows non-verbal tags– which is an extremely useful feature to guide realistic AI voices. Some examples of non-verbal tags you can use:(laughs), (clears throat), (sighs), (gasps), (coughs), (singing), (sings), (mumbles), (beep), (groans), (sniffs), (claps), (screams), (inhales), (exhales), (applause), (burps), (humming), (sneezes), (chuckle), (whistles).
Audio Prompt
- Audio Prompts are optional, but they essentially function as a voice cloning feature. Since Dia doesn’t offer a voice library and you get a random voice with each generation, and because you’ll often need to generate multiple outputs to cover longer scripts – this, in my opinion, becomes a must-use feature as it adds a layer of customization and consistency.
1. Upload audio
2. Write in the transcript in the text box, plus the text you want it to make new.
[S1] Stuff that I'm saying in the audio.
[S1] Goes here.
[S1] This has been my transcript.
[S1] This is my new text.
[S1] This is text I've never heard before.
[S1] Wow. Amazing! (laughs)
[S1] That was the text of the audio I never said.
3. Click generate"
Generation Parameters
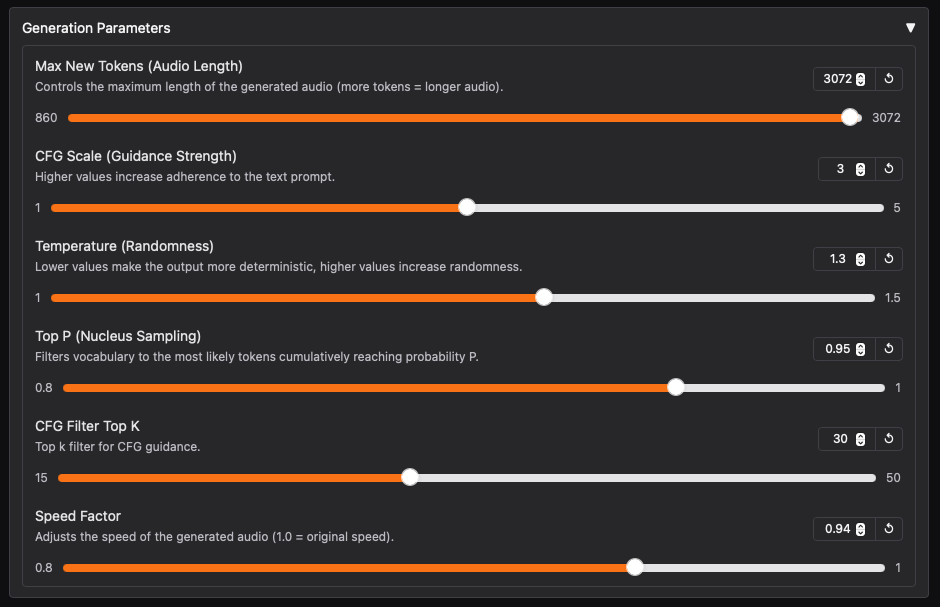
- Some parameters are fairly intuitive, such as
CFG Scale (Guidance Strength)orSpeed Factor, but others like theTop P (Nucleus Sampling)orCFG Filter Top Kare more advanced and rooted in machine learning concepts.
Generated Audio
- Stating the obvious: here you will see your generated audio output.
The making of The Green Spurt voiceover
After tweaking the input text script a bit and getting a better understanding of Dia, here’s what I did to get to the final result:
- Split the script into two parts, since I learned that Dia’s super-fast output voice I noticed in my initial tests was due to its current limitations, with each generation recommended to stay under 20 seconds.
- Used an audio prompt (voice cloning) for consistency across generations. I actually used an ElevenLabs voice output as the reference.
Yes, I trained one AI with the voice of another...
- While I knew from their Github guidelines that it’s recommended to provide the audio prompt transcript of the to-be cloned audio before the generation text, I skipped that in some tests and weirdly, I got better results. So I just went with it. Because of this, I also ended up using the same reference audio file for all generations.
- I actually misused the audio prompt feature at first by providing an audio sample shorter than recommended, which explained why the voice didn’t closely match my reference. When I went back and used it as intended, the voice cloning improved noticeably and the output sounded much closer to the voice I added to be cloned. But since I already had a good collection of generated audios, I decided to stick with those.
- Played a bit with the generation parameters, but in all honestly, I didn’t notice the differences. The output is still quite inconsistent overall, sometimes drastically different even when reusing the same input text, audio prompt, and parameters. So I used the default values for most of the generations.
- Used non-verbal tags: (sighs) and (laughs nervously).
- Generated different outputs, up to Hugging Face's max daily quotas on their Zero GPU queue which is 5 minutes per day. That gave me enough audio to work with.
Editing in Audacity
Once I got a good batch of generations, I used Audacity* to mix and match my favorite segments and add pauses where needed.

*Audacity is a free open-source software for recording and editing audio that runs on all major operating systems.
Final result 🥁
Extra tips if you want to try it yourself
- Carefully read the Generation Guidelines and Features before you start.
- Instead of chasing a perfect voiceover in a single take, generate multiple outputs and pick the best segments from each. You can easily stitch them together using a simple audio editor.
- Embrace the weirdness. If you need something stable and controllable, this model might not be the right one for your use case, at least not for now.
- Watch your headphones volume (seriously). Your generations could include weird artifacts that might give you a jump scare. In the same time, you will have some fun with the outputs as well!
Insights from the Dia community
If you are interested in this project, whether for creative projects or development, Nari Labs has an active Discord server that I recommend joining, especially as it seems the most reliable source of updates. Every time I checked over the past week, there were around 500 members online, which speaks to the momentum behind it.
Here are a few key takeaways from browsing the channels:
- ⚠️ narilabs dot org is not their website and they are not associated with any Web3 or Crypto entity.
- Multilingual is not supported officially as of now, but you can add an audio prompt in any language and provide "romanized" transcripts. Some people are trying it already in different languages (I have seen examples of Spanish, Japanese, Hindi and more) with fairly good results. If you are interested, you can find them posted in the #i-made-this channel.
- One of the most requested features is longer audio generation, the team is already working on it and getting contributions from the community.
- Overall, voice speed up is a known issue, and they might have solved it internally already. An update with the fix could be coming soon.
- Nari Labs is working with Hugging Face to port their model to transformers. This means easier training, fine-tuning, and faster inference in the future.
- They're building a free platform where you can create, remix, and share, using an improved version of Dia. You can join the waitlist here.
- When this was met with skepticism by one member who was suggesting they will go full Saas soon, Toby Kim (one of the creators) replied: "We're not planning a SaaS type product, we're going all in on B2C - we want you guys to have fun. We built Dia because we wanted to have fun with Voice Conversations."
Final Thoughts
Dia isn’t perfect, but if you work with its quirks rather than against them, it can deliver impressive results. It’s easily the most realistic and exciting TTS model I’ve worked with so far.
It's definitely not ready for high-stakes commercial work just yet, but that doesn’t appear to be Nari Labs’ intention. It’s a technical playground for research and educational use, and being open-source means developers can fine-tune it and build all kinds of cool projects on top of it.
I’ve worked with professional voice actors before, and I believe there’s no true substitute for the nuance and presence a human can bring. But in some cases, especially when time or budget is tight, AI voices can offer a practical, if imperfect, alternative.
I'll be keeping a close eye on future updates from Dia. What Nari Labs achieved as a team of two undergrads in just three months is seriously impressive. Kudos! 👏
With immersive regards from my digital persona!